不论是哪一种语言,并发编程都是一项非常重要的技巧。比如我们上一章用的爬虫,就被广泛用在工业的各个领域。我们每天在各个网站、App上获取的新闻信息,很大一部分都是通过并发编程版本的爬虫获得的。
正确并合理的使用并发编程,无疑会给我们的程序带来极大性能上的提升。今天我们就一起学习Python中的并发编程——Futures。
区分并发和并行
我们在学习并发编程时,常常会听到两个词:并发(Concurrency)和并行(Parallelism)这两个术语。这两者经常一起使用,导致很多人以为他们是一个意思,其实是不对的。
首先要辨别一个误区,在Python中,并发并不是只同一时刻上右多个操作(thread或者task)同时进行。相反,在某个特定的时刻上它只允许有一个操作的发生,只不过线程或任务之间会相互切换直到完成,就像下面的图里表达的
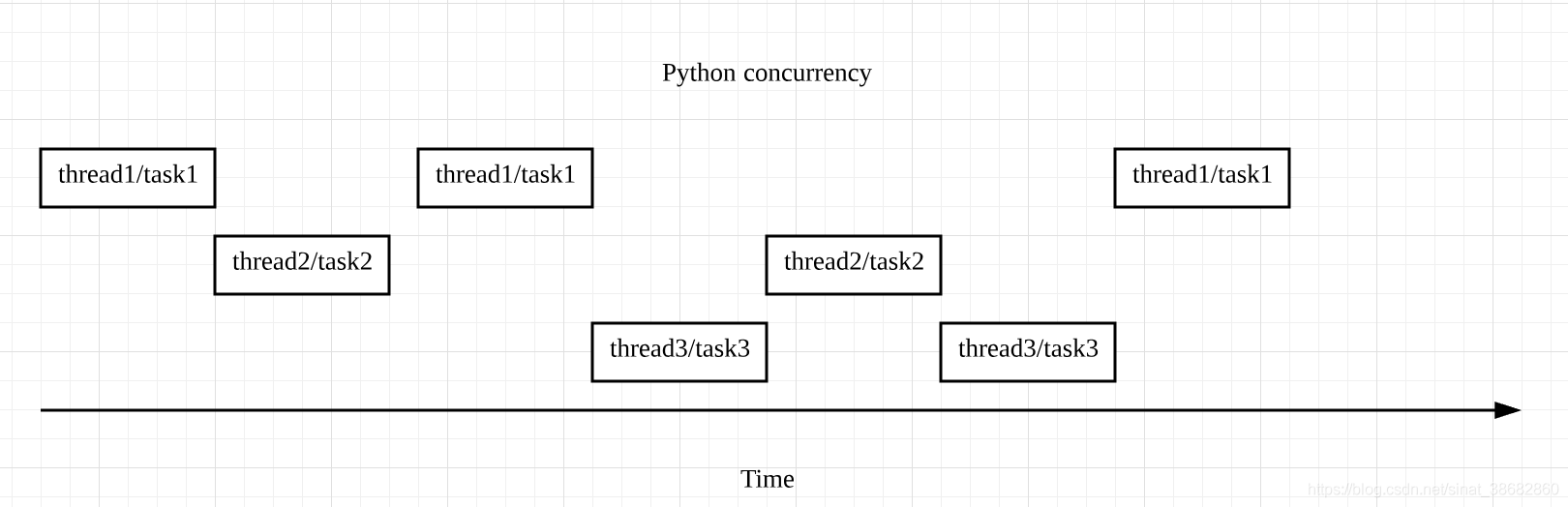
在上图中出现了task和thread两种切换顺序的不同方式。分别对应了Python中并发两种形式——threading和asyncio。
对于线程,操作系统知道每个线程的所有信息,因此他会做主在适当的时候做线程切换,这样的好处就是代码容易编写,因为程序员不需要做任何切换操作的处理;但是切换线程的操作,有可能出现在一个语句的执行过程中( 比如X =1),这样比较容易出现race condiiton的情况。
而对于asyncio,主程序想要切换任务的时候必须得到此任务可以被切换的通知,这样一来就可以避免出现上面的race condition的情况。
至于所谓的并行,只在同一时刻、同时发生。Python中的multi-Processing便是这个意思对应多进程,我们可以这么简单的理解,如果我们的电脑是8核的CPU,那么在运行程序时,我们可以强制Python开启8个进程,同时执行,用以加快程序的运行速度。大概是下面这个图的思路

对比看来,并发通常用于I/O操作频繁的场景。比方我们要从网站上下载多个文件,由于I/O操作的时间要比CPU操作的时长多的多,这时并发就比较适合。而在CPU使用比较heavy的场景中,为了加快运行速度,我们会多用几台机器,让多个处理器来运算。
还记得以前写了个博客总结过:在Python中的多线程是依靠CPU切换上下文实现的一种“伪多线程”,在进行大量线程切换过程中会占用比较多的CPU资源,而在进行IO操作时候(不论是在网络上进行数据交互还是从内存、硬盘上读写数据)是不需要CPU进行计算的。所以多线程只适用于IO操作密集的环境,不适用于计算密集型操作。
并发编程之Futures
单线程于多线程性能比较
我们下面通过一个实例,从代码的角度来理解并发编程中的Futures,并进一步比较其于单线程的性能区别
假设我们有个任务,从网站上下载一些内容然后打印出来,如果用单线程的方式是这样实现的
import requests
import time
def download_one(url):
resp = requests.get(url)
print('Read {} from {}'.format(len(resp.content),url))
def download_all(urls):
for url in urls:
download_one(url)
def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
download_all(sites)
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites),end_time-start_time))
if __name__ == '__main__':
main()
这是种最简单暴力最直接的方式:
先遍历存储网站的列表
对当前的网站进行下载操作
当前操作完成后,再对下一个网站进行同样的操作,一直到结束。
可以试出来总耗时大概是2s多,单线程的方式简单明了,但是最大的问题是效率低下,程序最大的时间都消耗在I/O等待上(这还是用的print,如果是写在硬盘上的话时间会更多)。如果在实际生产环境中,我们需要访问的网站至少是以万为单位的,所以这个方案根本行不通。
接着我们看看多线程版本的代码
import concurrent.futures
import requests
import threading
import time
def download_one(url):
resp = requests.get(url).content
print('Read {} from {}'.format(len(resp),url))
def download_all(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_one,sites)
def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
download_all(sites)
# for i in sites:
end_time = time.perf_counter()
# print('Down {} sites in {} seconds'.format(len(sites),end_time-start_time))
if __name__ == '__main__':
main()
这段代码的运行时长大概是0.2s,效率一下提升了10倍多,可以注意到这个版本和单线程的区别主要在下面:
def download_all(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_one,sites)
在上面的代码中我们创建了一个线程池,有5个线程可以分配使用。executer.map()与以前将的Python内置的map()函数,表示对sites中的每一个元素并发的调用函数download_one()函数。
顺便提一下,在download_one()函数中,我们使用的requests.get()方法是线程安全的(thread-safe),因此在多线程的环境下,它也可以安全使用,并不会出现race condition(条件竞争)的情况。
另外,虽然线程的数量可以自己定义,但是线程数并不是越多越好,以为线程的创建、维护和删除也需要一定的开销。所以如果设置的很大,反而会导致速度变慢,我们往往要根据实际的需求做一些测试,来寻找最优的线程数量。
当然,我们也可以用并行的方式去提高运行效率,只需要在download_all()函数中做出下面的变化即可
def download_all(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
to_do = []
for site in sites:
future = executor.submit(download_one,site)
to_do.append(site)
for future in concurrent.futures.as_completed(to_do):
future.result()
在需要改的这部分代码中,函数ProcessPoolExecutor()表示创建进程池,使用多个进程并行的执行程序。不过,这里 通常省略参数workers,因为系统会自动返回CPU的数量作为可以调用的进程数。
就像上面说的,并行方式一般用在CPU密集型的场景中,因为对于I/O密集型操作多数时间会用于等待,相比于多线程,使用多进程并不会提升效率,反而很多时候,因为CPU数量的限制,会导致执行效率不如多线程版本。
到底什么是Futures?
Python中的Futures,位于concurrent.futures和asyncio中,他们都表示带有延迟的操作,Futures会将处于等待状态的操作包裹起来放到队列中,这些操作的状态可以随时查询。而他们的结果或是异常,也能在操作后被获取。
通常,作为用户,我们不用考虑如何去创建Futures,这些Futures底层会帮我们处理好,我们要做的就是去schedule这些Futures的执行。比方说,Futures中的Executor类,当我们中的方法done(),表示相对应的操作是否完成——用True表示已完成,ongFalse表示未完成。不过,要注意的是done()是non-blocking的,会立刻返回结果,相对应的add_done_callback(fn),则表示Futures完成后,相对应的参数fn,会被通知并执行调用。
Futures里还有一个非常重要的函数result(),用来表示future完成后,返回器对应的结果或异常。而as_completed(fs),则是针对给定的future迭代器fs,在其完成后,返回完成后的迭代器。
所以也可以把上面的例子写成下面的形式:
def download_all(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
to_do = []
for site in sites:
future = executor.submit(download_one,site)
to_do.append(site)
for future in concurrent.futures.as_completed(to_do):
future.result()
这里,我们首先用executor.submit(),将下载每个网站的内容都放进future队列to_do里等待执行。然后是as_completed()函数,在future完成后输出结果
不过这里有个事情要注意一下:future列表中每个future完成的顺序和他在列表中的顺序不一定一致,至于哪个先完成,取决于系统的调度和每个future的执行时间。
为什么多线程每次只有一个线程执行?
前面我们讲过,在一个时刻下,Python主程序只允许有一个线程执行,所以Python的并发,是通过多线程的切换完成的,这是为什么呢?
这就又和以前讲的知识串联到一起了——GIL(全局解释器锁),这里在复习下:
事实上,Python的解释器并不是线程安全的,为了解决由此带来的race condition等问题,Python就引入了GIL,也就是在同一个时刻,只允许一个线程执行。当然,在进行I/O操作是,如果一个线程被block了,GIL就会被释放,从而让另一个线程能够继续执行。
总结
这节课里我们先学习了Python中并发和并行的概念
并发——通过线程(thread)和任务(task)之间相互切换的方式实现,但是同一时刻,只允许有一个线程或任务执行
并行——多个进程同时进行。
并发通常用于I/O频繁操作的场景,而并行则适用于CPU heavy的场景
随后我们通过一个下载网站内容的例子,比较了单线程和运用FUtures的多线程版本的性能差异,显而易见,合理的运用多线程,能够极大的提高程序运行效率。
我们还大致了解了Futures的方式,介绍了一些常用的函数,并辅以实例加以理解。
要注意,Python中之所以同一时刻只允许一个线程运行,其实是由于GIL的存在。但是对于I/O操作而言,当其被block的时候,GIL会被释放,使其他线程继续执行。
以上就是Python并发编程之未来模块Futures的详细内容,更多关于Python并发未来模块Futures的资料请关注Devmax其它相关文章!