不进行计算时,生成器和list空间占用
import time
from memory_profiler import profile
@profile(precision=4)
def list_fun():
start = time.time()
total = ([i for i in range(5000000)])
print('iter_spend_time:',time.time()-start)
@profile(precision=4)
def gent_func():
gent_start = time.time()
total = (i for i in range(5000000))
print('gent_spend_time:',time.time()-gent_start)
iter_fun()
gent_func()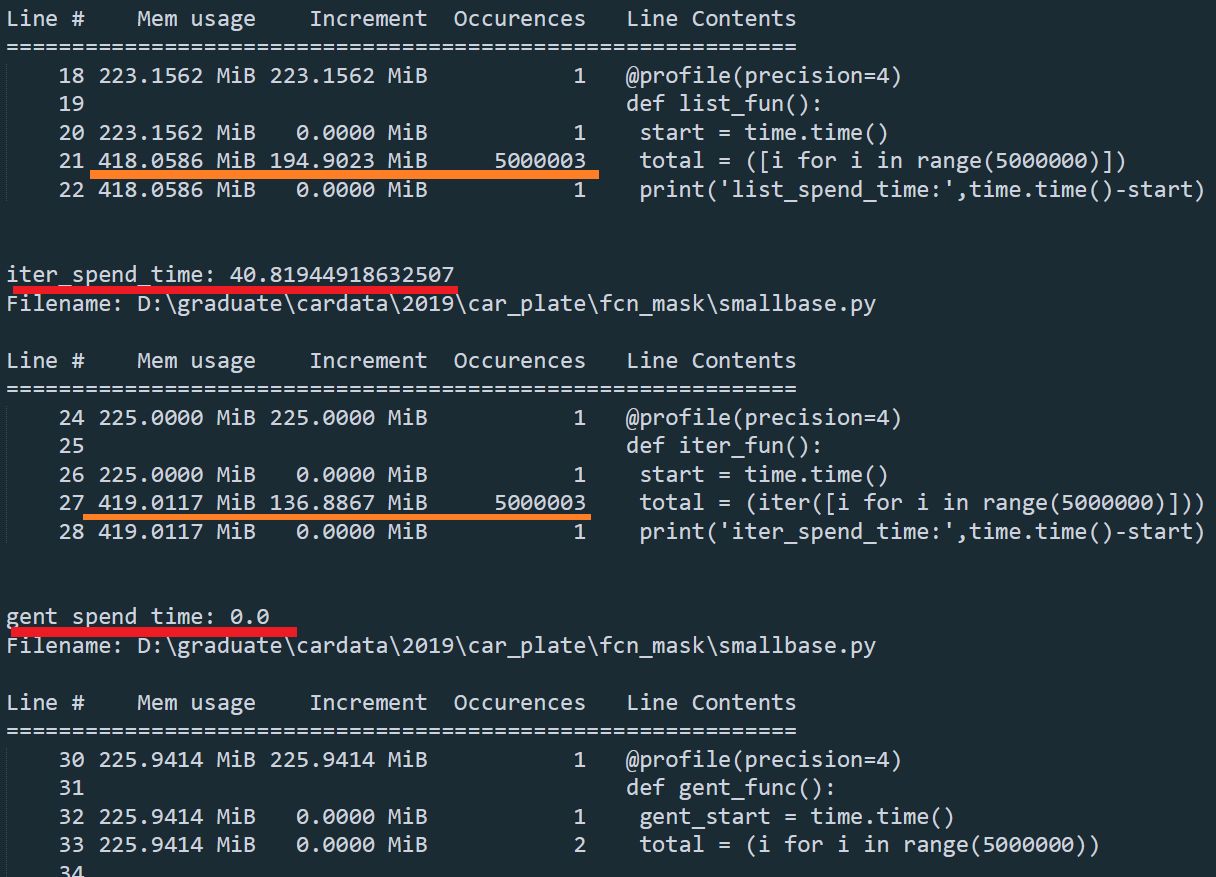
显示结果的含义:第一列表示已分析代码的行号,第二列(Mem 使用情况)表示执行该行后 Python 解释器的内存使用情况。第三列(增量)表示当前行相对于最后一行的内存差异。最后一列(行内容)打印已分析的代码。
分析:在不进行计算的情况下,列表list和迭代器会占用空间,但对于生成器不会占用空间
当需要计算时,list和生成器的花费时间和占用内存
使用sum内置函数,list和生成器求和10000000个数据,list内存占用较大,生成器花费时间大概是list的两倍
import time
from memory_profiler import profile
@profile(precision=4)
def iter_fun():
start = time.time()
total = sum([i for i in range(10000000)])
print('iter_spend_time:',time.time()-start)
@profile(precision=4)
def gent_func():
gent_start = time.time()
total = sum(i for i in range(10000000))
print('gent_spend_time:',time.time()-gent_start)
iter_fun()
gent_func()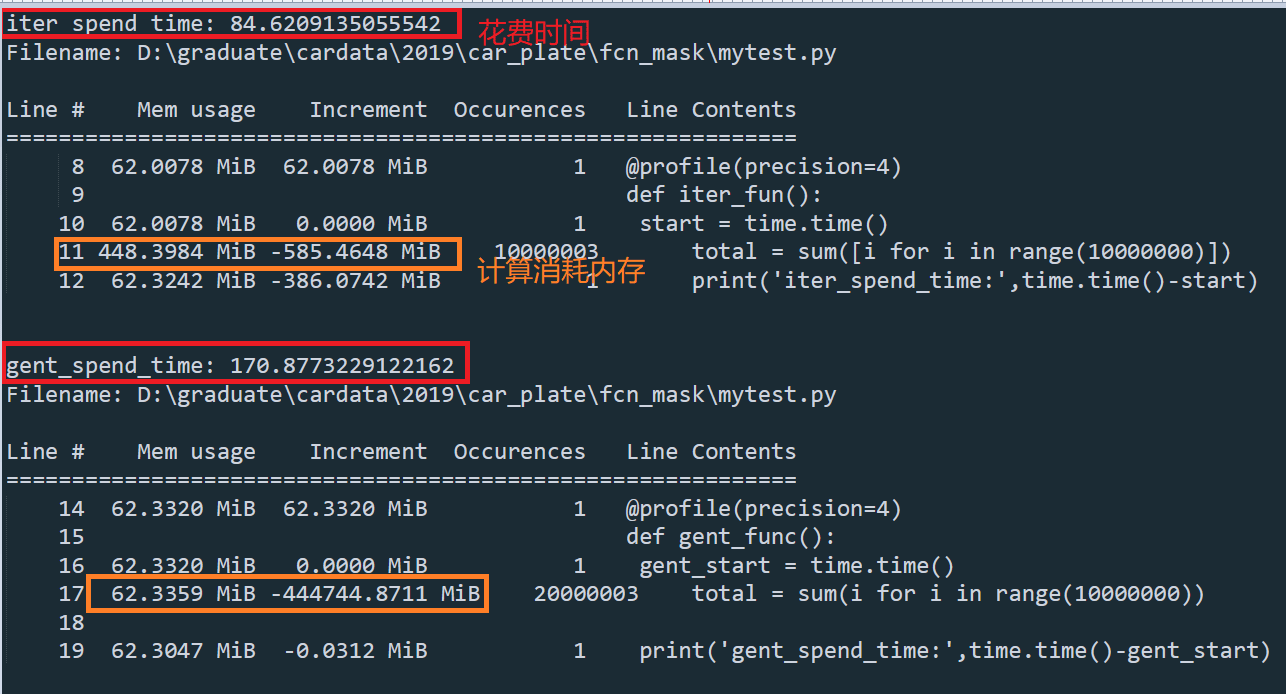
比较分析,如果需要对数据进行迭代使用时,生成器方法的耗时较长,但内存使用方面还是较少,因为使用生成器时,内存只存储每次迭代计算的数据。分析原因时个人认为,生成器的迭代计算过程中,在迭代数据和计算直接不断转换,相比与迭代器对象中先将数据全部保存在内存中(虽然占内存,但读取比再次迭代要快),因此,生成器比较费时间,但占用内存小。
记录数据循环求和500000个数据,迭代器和生成器循环得到时
总结:几乎同时完成,迭代器的占用内存较大
import time
from memory_profiler import profile
itery = iter([i for i in range(5000000)])
gent = (i for i in range(5000000))
@profile(precision=4)
def iter_fun():
start = time.time()
total= 0
for item in itery:
total =item
print('iter:',time.time()-start)
@profile(precision=4)
def gent_func():
gent_start = time.time()
total = 0
for item in gent:
total =item
print('gent:',time.time()-gent_start)
iter_fun()
gent_func()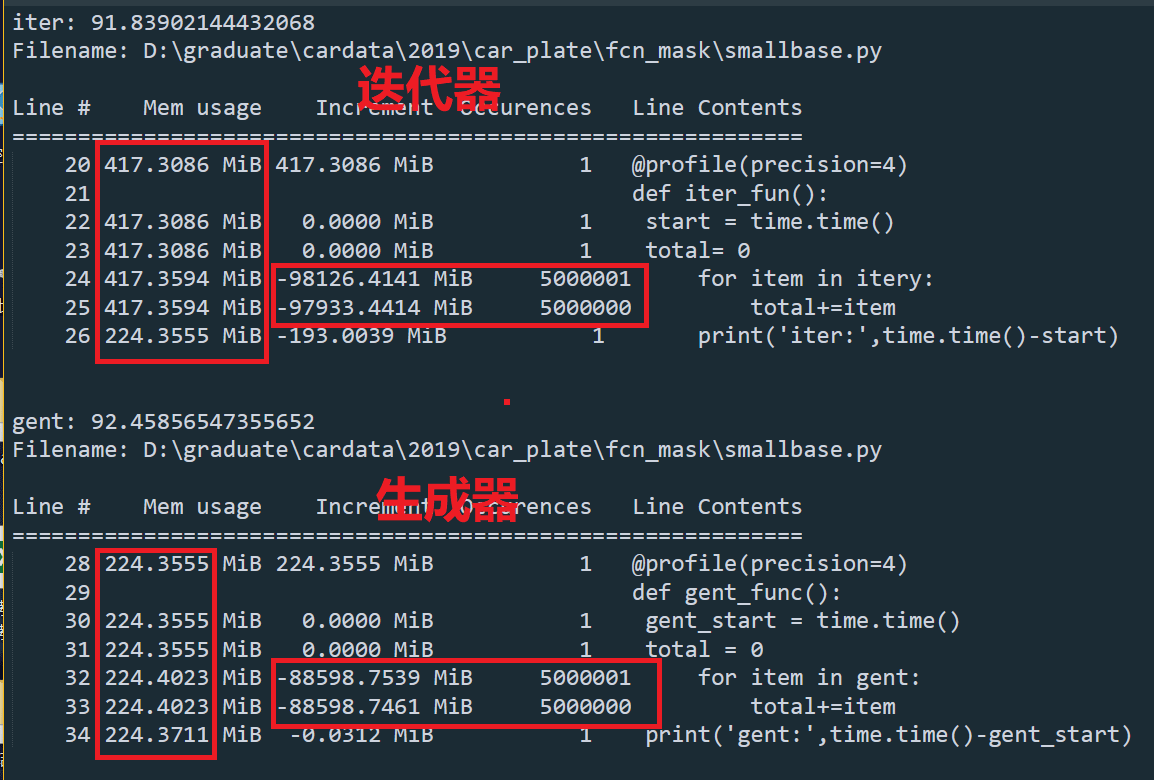
list,迭代器和生成器共同使用sum计算5000000个数据时间比较
总结:list sum和迭代器 sum计算时长差不多,但生成器 sum计算的时长几乎长一倍,
import time
from memory_profiler import profile
@profile(precision=4)
def list_fun():
start = time.time()
print('start!!!')
list_data = [i for i in range(5000000)]
total = sum(list_data)
print('iter_spend_time:',time.time()-start)
@profile(precision=4)
def iter_fun():
start = time.time()
total = 0
total = sum(iter([i for i in range(5000000)]))
print('total:',total)
print('iter_spend_time:',time.time()-start)
@profile(precision=4)
def gent_func():
gent_start = time.time()
total = sum(i for i in range(5000000))
print('total:',total)
print('gent_spend_time:',time.time()-gent_start)
list_fun()
iter_fun()
gent_func()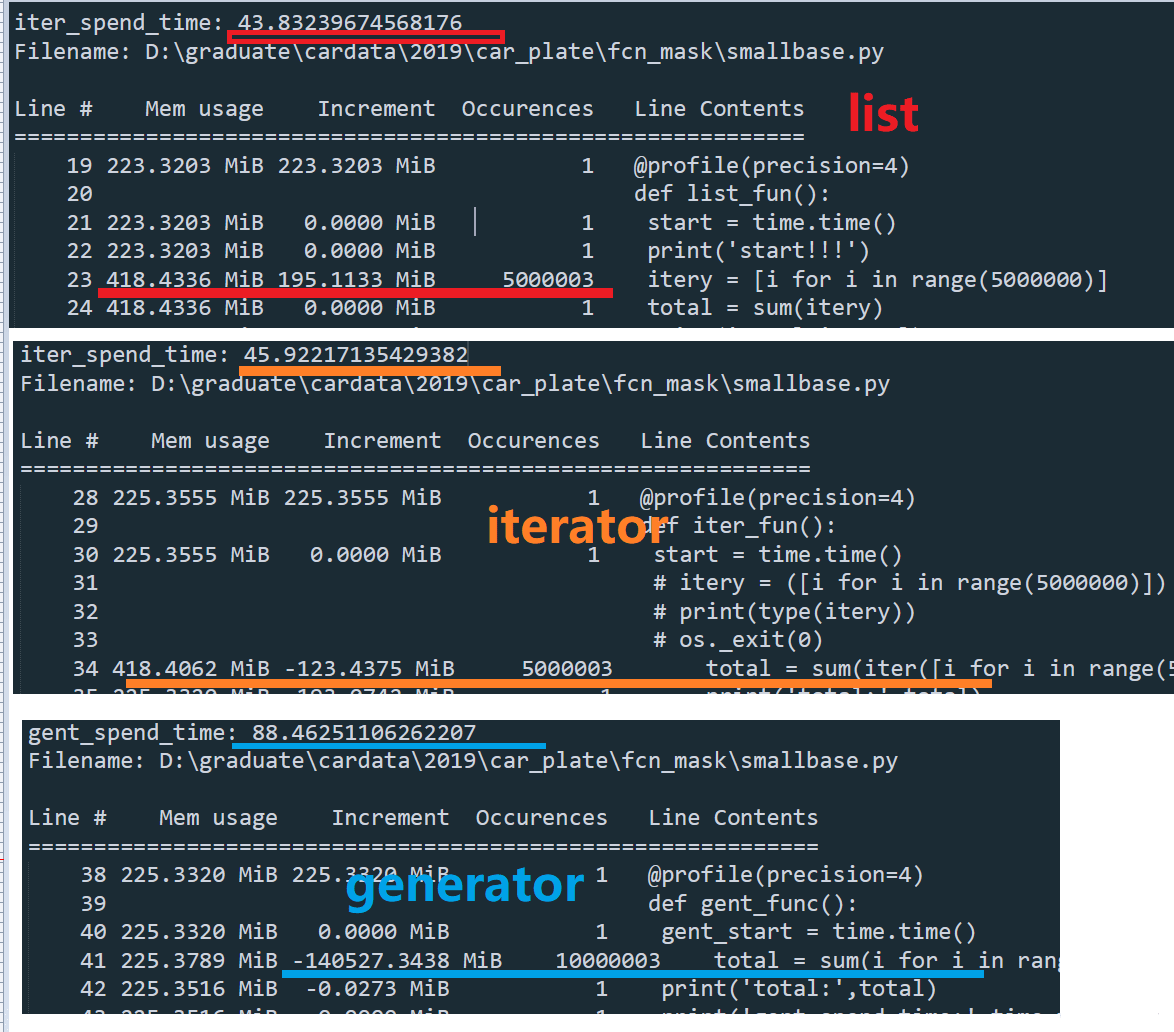
到此这篇关于python memory_profiler库生成器和迭代器内存占用的时间分析的文章就介绍到这了,更多相关python的memory_profiler 内容请搜索Devmax以前的文章或继续浏览下面的相关文章希望大家以后多多支持Devmax!