前言
我们之前学的单链表,默认只能从链表的头部遍历到链表的尾部,在实际中应用太少见,太局限;而双向链表,对于该链表中的任意节点,既可以通过该节点向前遍历,也可以通过该节点向后遍历,双向链表在实际工程中应用非常广泛,是使用链表这个结构的首选。
一、认识双向链表
单向链表不仅保存了当前的结点值,还保存了下一个结点的地址
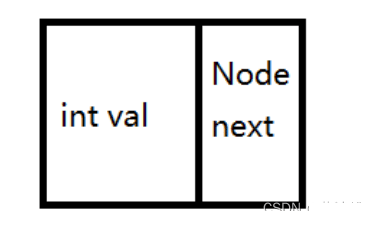
双向链表不仅保存了当前节点的值,还保存了上一个结点的地址和下一个结点的地址

定义一个双向链表的结点类:
结点中既要保存当前节点的值,还要保存此节点的前驱节点的地址和此节点的后继节点的地址
class DoubleNode{
public DoubleNode next;
DoubleNode prev;
int val;
DoubleNode tail;
public DoubleNode() {}
public DoubleNode(int val) {
this.val = val;
}
public DoubleNode(DoubleNode prev, int val, DoubleNode tail) {
this.prev = prev;
this.val = val;
this.tail = tail;
}
}定义一个双向链表类:
既可以从前向后,也可以从后向前,所以在这个类中,即保存一下头结点,也保存一下尾结点的值
public class DoubleLinkedList {
private int size;
private DoubleNode head;
private DoubleNode tail;
}二、双向链表的增删改查
1.插入
头插
在当前链表的头部插入一个节点,让当前链表的头结点head前驱指向要插入的节点node,然后让node的后继指向head,然后让head = node,让node成为链表的头结点
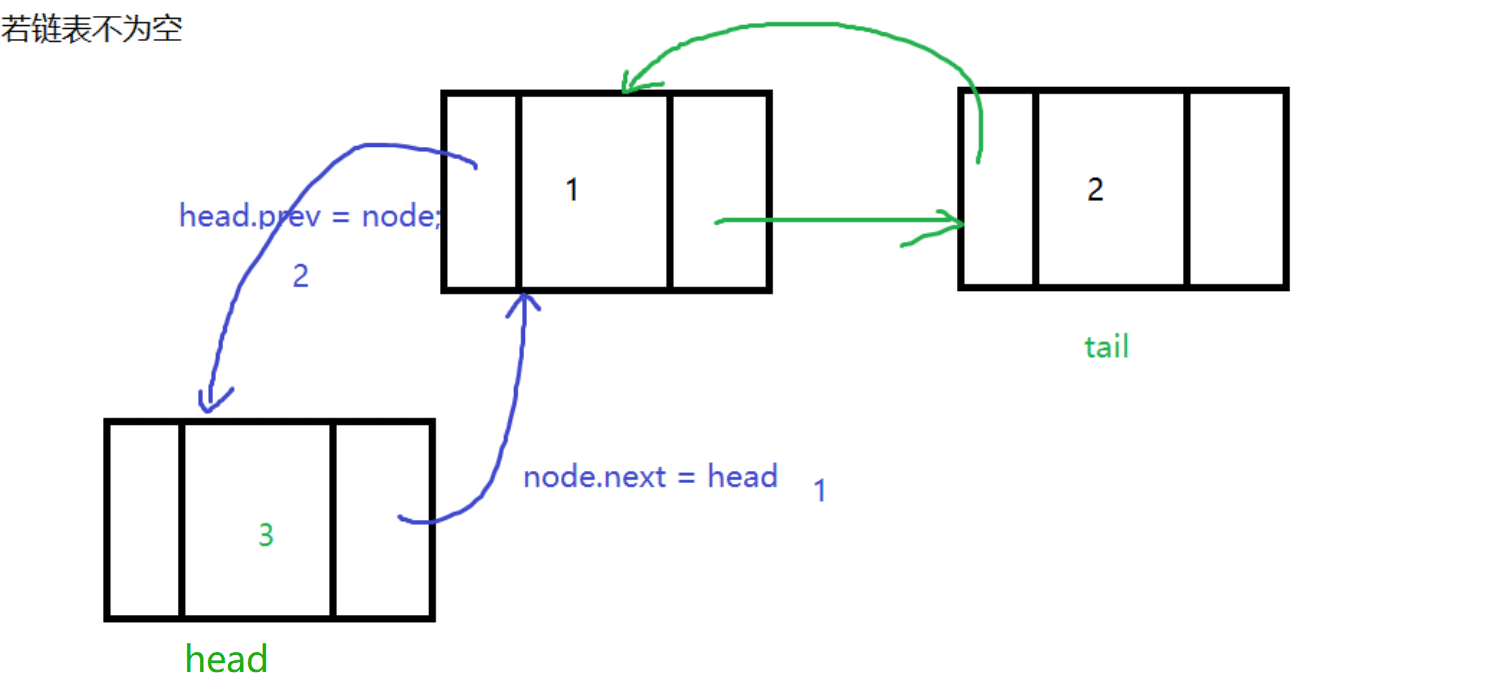
代码如下:
/**
* 头插
*/
public void addFirst(int val){
DoubleNode node = new DoubleNode(val);
if (head == null){
head = tail = node;
}else{
node.next = head;
head.prev = node;
head = node;
}
size ;
}尾插
和头插一样,只不过在链表的尾部插入
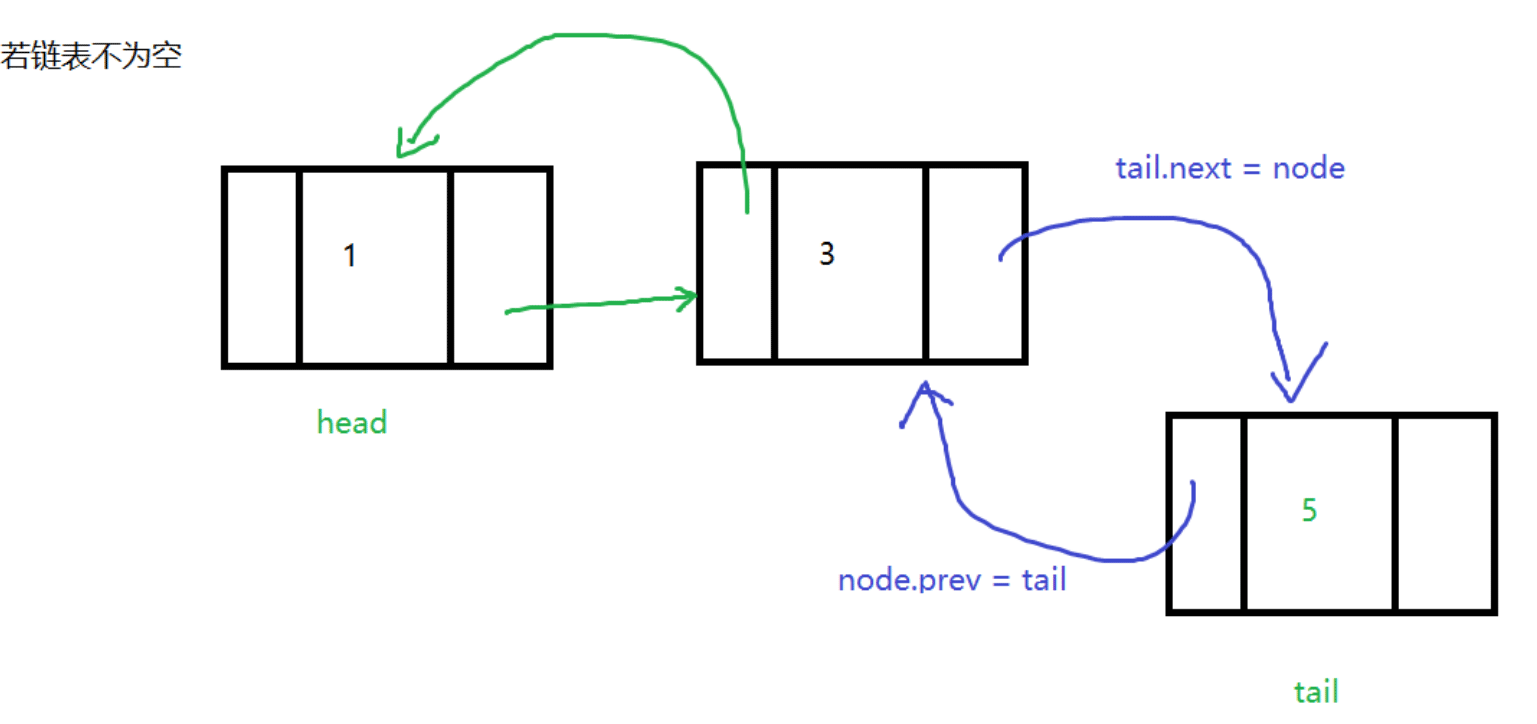
代码如下:
public void addLast(int val){
DoubleNode node = new DoubleNode(val);
if (head == null){
head = tail =node;
}else{
tail.next = node;
node.prev = tail;
tail = node;
}
size ;
}在index位置插入
在索引为index的位置插入值为val的节点:
插入还是要找前驱节点,但双向链表找前驱节点比单向链表找前驱节点要灵活很多,单向链表只能从头走到尾,假如此时有100个节点,要在索引为98的位置插入节点,那么双向链表就可以从尾结点开始找,会方便很多
如何判断从前向后找,还是从后向前找?
- 1.index < size / 2 – >从前向后找,插入位置在前半部分
- 2.index > size / 2 – >从后向前找,插入位置在后半部分
代码如下:
/**
* 在index位置插入
* @param index
* @param val
*/
public void add(int index,int val){
DoubleNode cur = new DoubleNode(val);
if (index < 0 || index > size){
System.err.println("add index illegal");
return;
}else{
if (index == 0){addFirst(val);}
else if (index == size){addLast(val);}
else{
DoubleNode prev = node(index-1);
DoubleNode next = prev.next;
cur.next = next;
next.prev = cur;
prev.next = cur;
cur.prev = prev;
}
}
size ;
}
/**
* 根据索引值找到对应的结点
* @param index
* @return
*/
private DoubleNode node(int index){
DoubleNode x = null;
if (index < size/2){
x = head;
for (int i = 0; i < index; i ) {
x = x.next;
}
}else{
x = tail;
for (int i = size - 1; i > index ; i--) {
x = x.prev;
}
}
return x;
}2.修改
代码如下:
/**
* 修改双向链表index位置的结点值为newVal
*/
public int set(int index,int newVal){
DoubleNode dummyHead = new DoubleNode();
dummyHead.next = head;
DoubleNode prev = dummyHead;
DoubleNode cur = prev.next;
if (index < 0 || index > size - 1){
System.err.println("set index illegal");
}else{
for (int i = 0; i < index; i ) {
prev = prev.next;
cur = cur.next;
}
}
int oldVal = cur.val;
cur.val = newVal;
return oldVal;
}3.查询
代码如下:
/**
* 查询index位置的结点值
*/
public int get(int index){
DoubleNode dummyHead = new DoubleNode();
dummyHead.next = head;
DoubleNode prev = dummyHead;
DoubleNode cur = prev.next;
if (index < 0 || index > size - 1){
System.err.println("get index illegal");
}else{
for (int i = 0; i < index; i ) {
prev = prev.next;
cur = cur.next;
}
}
return cur.val;
}4.删除
删除index位置的节点
代码如下:
//删除链表index位置的结点
public void removeIndex(int index){
if (index < 0 || index > size - 1){
System.err.println("remove index illegal");
return;
}
DoubleNode cur = node(index);
unlink(cur);
}
/**
* 删除当前双向链表的node结点
* 分治法
* @param node
*/
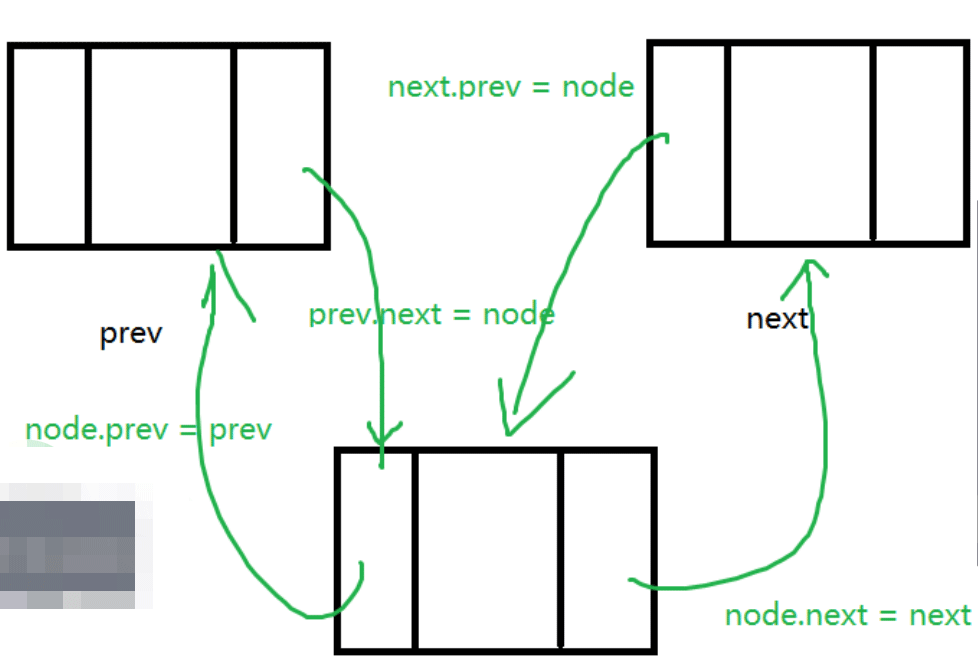
private void unlink (DoubleNode node){
DoubleNode prev = node.prev;
DoubleNode successor = node.next;
//1.先处理node的前半部分
if (prev == null){
head = successor;
}else{
//前驱不为空的情况
prev.next = successor;
node.prev = null;
}
if (successor == null){
tail = prev;
}else{
successor.prev = prev;
node.next = null;
}
size--;
}头删
调用删除任意位置的节点即可
代码如下:
//头删
public void removeFirst(){
removeIndex(0);
}尾删
调用删除任意位置的节点即可
代码如下:
//尾删
public void removeLast(){
removeIndex(size - 1);
}删除第一个值为val的节点
代码如下:
//删除第一个值为val的结点
public void removeValOnce(int val){
if (head == null){
return;
}
for (DoubleNode x = head;x != null;x = x.next){
if (x.val == val){
unlink(x);
break;
}
}
}
/**
* 删除当前双向链表的node结点
* 分治法
* @param node
*/
private void unlink (DoubleNode node){
DoubleNode prev = node.prev;
DoubleNode successor = node.next;
//1.先处理node的前半部分
if (prev == null){
head = successor;
}else{
//前驱不为空的情况
prev.next = successor;
node.prev = null;
}
if (successor == null){
tail = prev;
}else{
successor.prev = prev;
node.next = null;
}
size--;
}删除所有值为val的值
代码如下:
//删除链表中所有值为val的结点
public void removeAllVal(int val){
for (DoubleNode x = head;x != null;){
if (x.val == val){
//暂存一下x的下一个结点
DoubleNode next = x.next;
unlink(x);
x = next;
}else{
//val不是待删除的元素
x = x.next;
}
}
}
/**
* 删除当前双向链表的node结点
* 分治法
* @param node
*/
private void unlink (DoubleNode node){
DoubleNode prev = node.prev;
DoubleNode successor = node.next;
//1.先处理node的前半部分
if (prev == null){
head = successor;
}else{
//前驱不为空的情况
prev.next = successor;
node.prev = null;
}
if (successor == null){
tail = prev;
}else{
successor.prev = prev;
node.next = null;
}
size--;
}总结
本篇博客带大家了解了一下什么是双向链表,和单链表有什么区别,已经双向链表的一些基本的增删改查的操作,
到此这篇关于Java双向链表的操作的文章就介绍到这了,更多相关Java双向链表内容请搜索Devmax以前的文章或继续浏览下面的相关文章希望大家以后多多支持Devmax!