1. 为什么需要Simhash?
传统相似度算法:文本相似度的计算,一般使用向量空间模型(VSM),先对文本分词,提取特征,根据特征建立文本向量,把文本之间相似度的计算转化为特征向量距离的计算,如欧式距离、余弦夹角等。
缺点:大数据情况下复杂度会很高。
Simhash应用场景:计算大规模文本相似度,实现海量文本信息去重。
Simhash算法原理:通过hash值比较相似度,通过两个字符串计算出的hash值,进行异或操作,然后得到相差的个数,数字越大则差异越大。
2. 文章关键词特征提取算法TD-IDF
词频(TF):一个词语在整篇文章中出现的次数与词语总个数之比;
逆向词频(IDF):一个词语,在所有文章中出现的频率都非常高,这个词语不具有代表性,就可以降低其作用,也就是赋予其较小的权值。
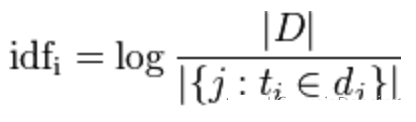
分子代表文章总数,分母表示该词语在这些文章出现的篇数。一般会采取分母加一的方法,防止分母为0的情况出现,在这个比值之后取对数,就是IDF了。
最终用tf*idf得到一个词语的权重,进而计算一篇文章的关键词。然后根据每篇文章对比其关键词的方法来对文章进行去重。simhash算法对效率和性能进行平衡,既可以很少的对比(关键词不能取太多),又能有好的代表性(关键词不能过少)。
3. Simhash原理
Simhash是一种局部敏感hash。即假定A、B具有一定的相似性,在hash之后,仍然能保持这种相似性,就称之为局部敏感hash。
得到一篇文章关键词集合,通过hash的方法把关键词集合hash成一串二进制,直接对比二进制数,其相似性就是两篇文档的相似性,在查看相似性时采用海明距离,即在对比二进制的时候,看其有多少位不同,就称海明距离为多少。
将文章simhash得到一串64位的二进制,根据经验一般取海明距离为3作为阈值,即在64位二进制中,只要有三位以内不同,就可以认为两个文档是相似的,这里的阈值也可以根据自己的需求来设置。也就是把一个文档hash之后得到一串二进制数的算法,称这个hash为simhash。
simhash具体实现步骤如下:
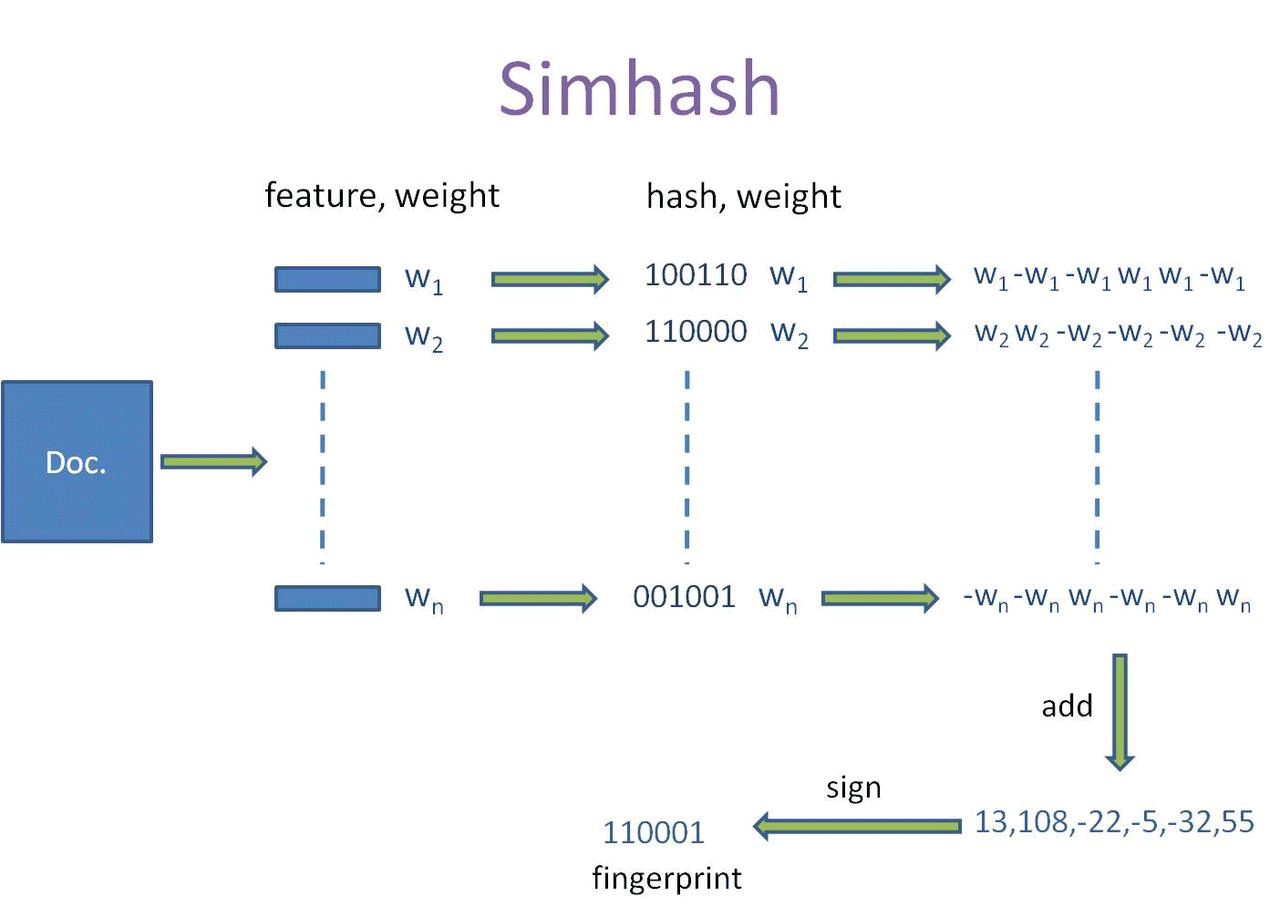
- 1. 将文档分词,取一个文章的TF-IDF权重最高的前20个词(feature)和权重(weight)。即一篇文档得到一个长度为20的(feature:weight)的集合。
- 2. 对其中的词(feature),进行普通的哈希之后得到一个64为的二进制,得到长度为20的(hash : weight)的集合。
- 3. 根据(2)中得到一串二进制数(hash)中相应位置是1是0,对相应位置取正值weight和负值weight。例如一个词进过(2)得到(010111:5)进过步骤(3)之后可以得到列表[-5,5,-5,5,5,5]。由此可以得到20个长度为64的列表[weight,-weight...weight]代表一个文档。
- 4. 对(3)中20个列表进行列向累加得到一个列表。如[-5,5,-5,5,5,5]、[-3,-3,-3,3,-3,3]、[1,-1,-1,1,1,1]进行列向累加得到[-7,1,-9,9,3,9],这样,我们对一个文档得到,一个长度为64的列表。
- 5. 对(4)中得到的列表中每个值进行判断,当为负值的时候去0,正值取1。例如,[-7,1,-9,9,3,9]得到010111,这样就得到一个文档的simhash值了。
- 6. 计算相似性。两个simhash取异或,看其中1的个数是否超过3。超过3则判定为不相似,小于等于3则判定为相似。
Simhash整体流程图如下:
4. Simhash的不足
完全无关的文本正好对应成了相同的simhash,精确度并不是很高,而且simhash更适用于较长的文本,但是在大规模语料进行去重时,simhash的计算速度优势还是很不错的。
5. Simhash算法实现
# !/usr/bin/python
# coding=utf-8
class Simhash:
def __init__(self, tokens='', hashbits=128):
self.hashbits = hashbits
self.hash = self.simhash(tokens)
def __str__(self):
return str(self.hash)
# 生成simhash值
def simhash(self, tokens):
v = [0] * self.hashbits
for t in [self._string_hash(x) for x in tokens]: # t为token的普通hash值
for i in range(self.hashbits):
bitmask = 1 << i
if t & bitmask:
v[i] = 1 # 查看当前bit位是否为1,是的话将该位 1
else:
v[i] -= 1 # 否则的话,该位-1
fingerprint = 0
for i in range(self.hashbits):
if v[i] >= 0:
fingerprint = 1 << i
return fingerprint # 整个文档的fingerprint为最终各个位>=0的和
# 求海明距离
def hamming_distance(self, other):
x = (self.hash ^ other.hash) & ((1 << self.hashbits) - 1)
tot = 0
while x:
tot = 1
x &= x - 1
return tot
# 求相似度
def similarity(self, other):
a = float(self.hash)
b = float(other.hash)
if a > b:
return b / a
else:
return a / b
# 针对source生成hash值
def _string_hash(self, source):
if source == "":
return 0
else:
x = ord(source[0]) << 7
m = 1000003
mask = 2 ** self.hashbits - 1
for c in source:
x = ((x * m) ^ ord(c)) & mask
x ^= len(source)
if x == -1:
x = -2
return x测试:
if __name__ == '__main__':
s = 'This is a test string for testing'
hash1 = Simhash(s.split())
s = 'This is a string testing 11'
hash2 = Simhash(s.split())
print(hash1.hamming_distance(hash2), " ", hash1.similarity(hash2))到此这篇关于如何利用python实现Simhash算法的文章就介绍到这了,更多相关pythonSimhash算法内容请搜索Devmax以前的文章或继续浏览下面的相关文章希望大家以后多多支持Devmax!