包括如何处理假的200页面/404智能判断等
喜欢用Python写脚本的小伙伴可以跟着一起写一写呀。
编写环境:Python2.x
00x1:模块
需要用到的模块如下:
import request
00x2:请求基本代码
先将请求的基本代码写出来:
import requests
def dir(url):
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'}
req = requests.get(url=url,headers=headers)
print req.status_code
dir('http://www.hackxc.cc')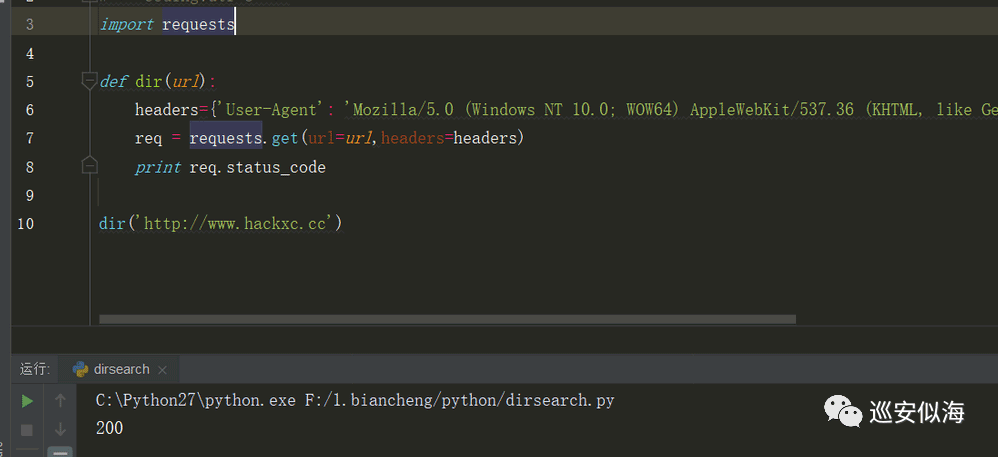
00x3:设置
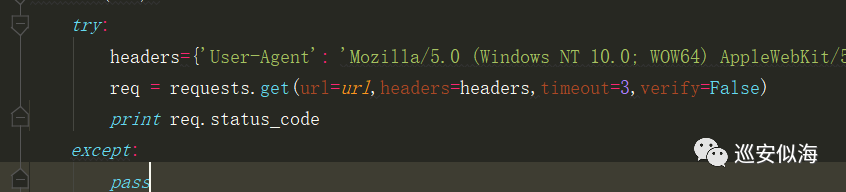
设置超时时间,以及忽略不信任证书
import urllib3 urllib3.disable_warnings() req = requests.get(url=url,headers=headers,timeout=3,verify=False)
再加个异常处理
调试一下
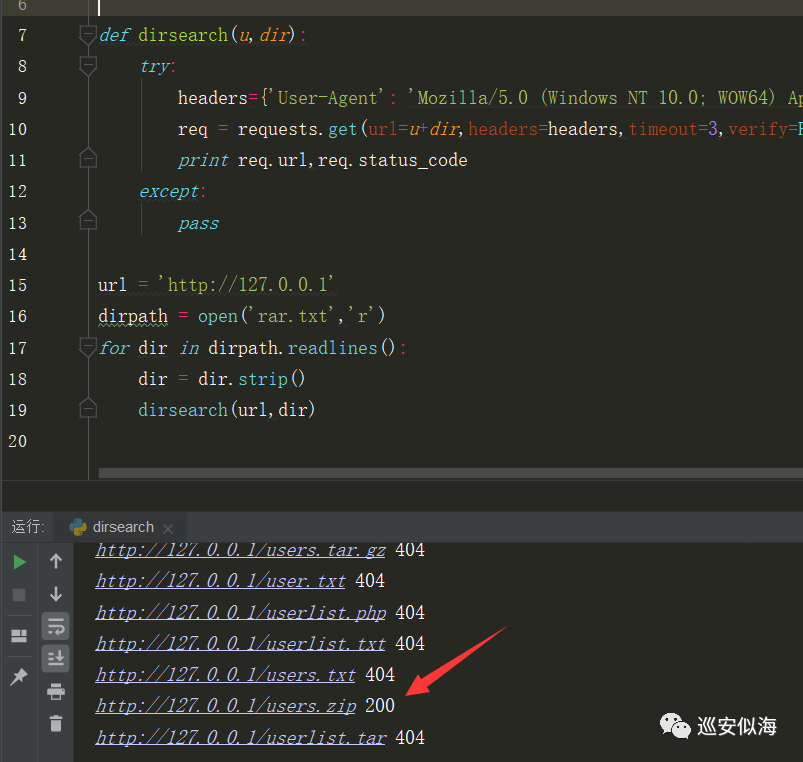
再进行改进,如果为200则输出
if req.status_code==200:
print "[*]",req.url00x4:200页面处理
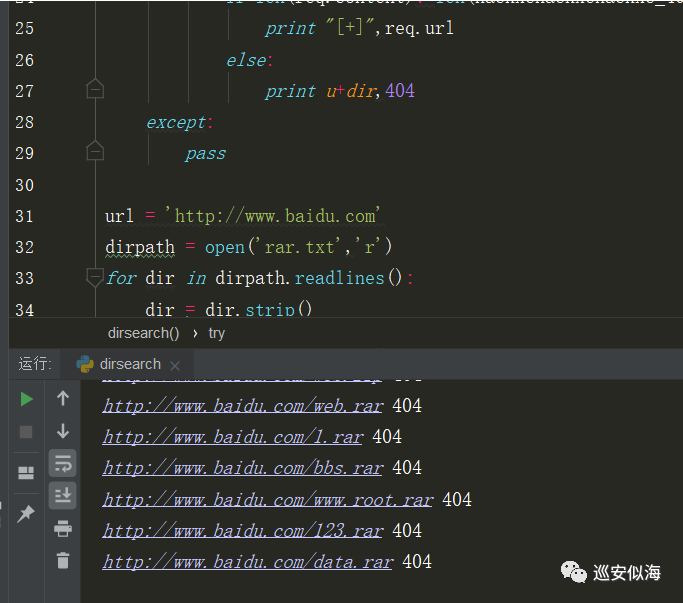
难免会碰到假的200页面,我们再处理一下
处理思路:
首先访问hackxchackxchackxc.php和xxxxxxxxxx记录下返回的页面的内容长度,然后在后来的扫描中,返回长度等于这个长度的判定为404
def dirsearch(u,dir):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'}
#假的200页面进行处理
hackxchackxchackxc = '/hackxchackxchackxc.php'
hackxchackxchackxc_404 =requests.get(url=u hackxchackxchackxc,headers=headers)
# print len(hackxchackxchackxc_404.content)
xxxxxxxxxxxx = '/xxxxxxxxxxxx'
xxxxxxxxxxxx_404 = requests.get(url=u xxxxxxxxxxxx, headers=headers)
# print len(xxxxxxxxxxxx_404.content)
#正常扫描
req = requests.get(url=u dir,headers=headers,timeout=3,verify=False)
# print len(req.content)
if req.status_code==200:
if len(req.content)!=len(hackxchackxchackxc_404.content)and len(req.content)!= len(xxxxxxxxxxxx_404.content):
print "[ ]",req.url
else:
print u dir,404
except:
pass很nice
00x5:保存结果
再让结果自动保存
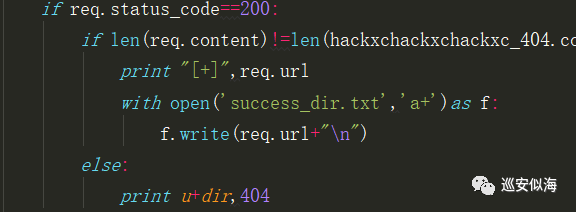
0x06:完整代码
#!/usr/bin/python
#-*- coding:utf-8 -*-
import requests
import urllib3
urllib3.disable_warnings()
urls = []
def dirsearch(u,dir):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'}
#假的200页面进行处理
hackxchackxchackxc = '/hackxchackxchackxc.php'
hackxchackxchackxc_404 =requests.get(url=u hackxchackxchackxc,headers=headers)
# print len(hackxchackxchackxc_404.content)
xxxxxxxxxxxx = '/xxxxxxxxxxxx'
xxxxxxxxxxxx_404 = requests.get(url=u xxxxxxxxxxxx, headers=headers)
# print len(xxxxxxxxxxxx_404.content)
#正常扫描
req = requests.get(url=u dir,headers=headers,timeout=3,verify=False)
# print len(req.content)
if req.status_code==200:
if len(req.content)!=len(hackxchackxchackxc_404.content)and len(req.content)!= len(xxxxxxxxxxxx_404.content):
print "[ ]",req.url
with open('success_dir.txt','a ')as f:
f.write(req.url "\n")
else:
print u dir,404
else:
print u dir, 404
except:
pass
if __name__ == '__main__':
url = raw_input('\nurl:')
print ""
if 'http' not in url:
url = 'http://' url
dirpath = open('rar.txt','r')
for dir in dirpath.readlines():
dir = dir.strip()
dirsearch(url,dir)以上就是PyHacker实现网站后台扫描器编写指南的详细内容,更多关于PyHacker网站后台扫描器的资料请关注Devmax其它相关文章!