前言
数组、链表、树等数据结构会存储元素的内容,一旦数据量过大,消耗的内存也会呈现线性增长
所以布隆过滤器是为了解决数据量大的一种数据结构
讲述布隆过滤器的时候需要了解一些预备的知识点:比如哈希函数
1. 预备知识
1.1 哈希函数
哈希函数指将哈希表中元素的关键键值映射为元素存储位置的函数
一般的线性表,树中,记录在结构中的相对位置是随机的,即和记录的关键字之间不存在确定的关系,因此,在结构中查找记录时需进行一系列和关键字的比较。这一类查找方法建立在“比较“的基础上,查找的效率依赖于查找过程中所进行的比较次数。 理想的情况是能直接找到需要的记录,因此必须在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使每个关键字和结构中一个唯一的存储位置相对应
具体其构造器的方法有:
直接定址法、数字分析法、平方取中法、折叠法、除留余数法等
解决其冲突的方法有:
拉链法、多哈希法、开放地址法、建域法等
2. 布隆过滤器
2.1 概念
它实际上是一个很长的二进制向量和一系列随机映射函数。(位数组和哈希函数)
布隆过滤器可以用于检索一个元素是否在一个集合中。
它的优点是空间效率和查询时间都比一般的算法要好的多(更加高效,存储空间小)
缺点是有一定的误识别率和删除困难
2.2 实现原理
之所以要用布隆过滤器,是因为HashMap 的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,而且数据大了之后不可能一次性
比如存储码农研究僧这个值,通过三个哈希函数,算得三个哈希值,存放在3个位置中(位数组)
之后判定查询码农博士僧的时候,发现这三个值只要有1个没有为1,就是没存储到,也就是没在集合中
但是如果存储的值很多,再去查找的时候,可能会出现一定的误判率,导致本身没在集合中,但位数组却都是1的情况
具体如何选择上面所说的位数组长度和哈希函数的个数呢
布隆器如果过小,导致很多位置都很快是1,误判率就很很高,如果布隆器过长,误判率会越小
哈希函数的个数如果过少,其速度慢,误判率也高,如果哈希函数的个数过多,其位1的速度加快,导致布隆过滤器的效率越低
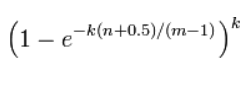
2.3 步骤
添加元素的具体的步骤是
将添加的元素给k个哈希函数算出对应位数组上的k个位置,将这k个位置设为1
查询元素的具体步骤是
将要查询的元素给k个哈希函数算出对应于位数组上的k个位置,如果k个位置有一个为0,则肯定不在集合中。如果k个位置全部为1,则可能在集合中
在计数布隆过滤器中,进行删除的前提是必须保证,值一定存在。因此单通过布隆过滤器无法保证值一定存在。如果通过其他的方法确认值存在后进行删除,则不能保证该值在后续布隆过滤器查询时一定返回不存在,因为该值相对应的位置并不一定为零。但确实可以一定概率上优化查询的效率。因此不能说计数布隆过滤器支持删除,应该说计数布隆过滤器提供了实现删除的可能
2.4 实现
public class MyBloomFilter {
/**
* 一个长度为10 亿的比特位
*/
private static final int DEFAULT_SIZE = 256 << 22;
/**
* 为了降低错误率,使用加法hash算法,所以定义一个8个元素的质数数组
*/
private static final int[] seeds = {3, 5, 7, 11, 13, 31, 37, 61};
/**
* 相当于构建 8 个不同的hash算法
*/
private static HashFunction[] functions = new HashFunction[seeds.length];
/**
* 初始化布隆过滤器的 bitmap
*/
private static BitSet bitset = new BitSet(DEFAULT_SIZE);
/**
* 添加数据
*
* @param value 需要加入的值
*/
public static void add(String value) {
if (value != null) {
for (HashFunction f : functions) {
//计算 hash 值并修改 bitmap 中相应位置为 true
bitset.set(f.hash(value), true);
}
}
}
/**
* 判断相应元素是否存在
* @param value 需要判断的元素
* @return 结果
*/
public static boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (HashFunction f : functions) {
ret = bitset.get(f.hash(value));
//一个 hash 函数返回 false 则跳出循环
if (!ret) {
break;
}
}
return ret;
}
/**
* 测试。。。
*/
public static void main(String[] args) {
for (int i = 0; i < seeds.length; i ) {
functions[i] = new HashFunction(DEFAULT_SIZE, seeds[i]);
}
// 添加1亿数据
for (int i = 0; i < 100000000; i ) {
add(String.valueOf(i));
}
String id = "123456789";
add(id);
System.out.println(contains(id)); // true
System.out.println("" contains("234567890")); //false
}
}
class HashFunction {
private int size;
private int seed;
public HashFunction(int size, int seed) {
this.size = size;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i ) {
result = seed * result value.charAt(i);
}
int r = (size - 1) & result;
return (size - 1) & result;
}
}
到此这篇关于Java布隆过滤器的原理和实现分析的文章就介绍到这了,更多相关Java布隆过滤器内容请搜索Devmax以前的文章或继续浏览下面的相关文章希望大家以后多多支持Devmax!