Prim算法介绍
1.点睛
在生成树的过程中,把已经在生成树中的节点看作一个集合,把剩下的节点看作另外一个集合,从连接两个集合的边中选择一条权值最小的边即可。
2.算法介绍
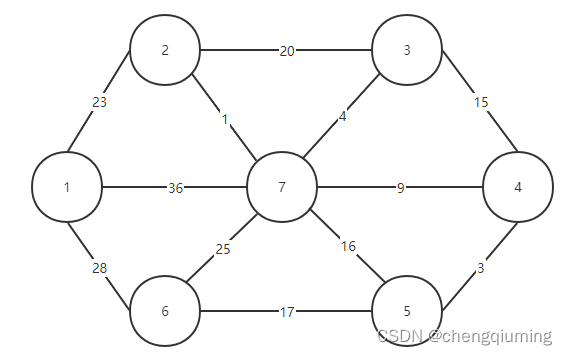
首先任选一个节点,例如节点1,把它放在集合 U 中,U={1},那么剩下的节点为 V-U={2,3,4,5,6,7},集合 V 是图的所有节点集合。
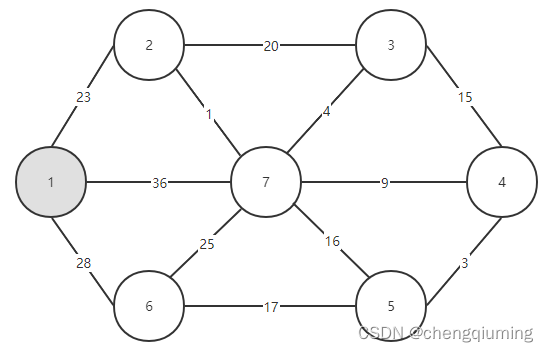
现在只需要看看连接两个集合(U 和 V-U)的边中,哪一条边的权值最小,把权值最小的边关联的节点加入集合 U 中。从上图可以看出,连接两个集合的 3 条边中,1-2 边的权值最小,选中它,把节点 2 加入集合 U 中,U={1,2},V - U={3,4,5,6},如下图所示。
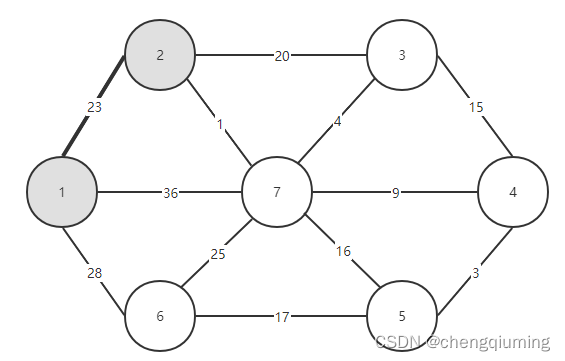
再从连接两个集合(U 和 V-U)的边中选择一条权最小的边。从上图看出,在连接两个集合的4条边中,节点2到节点7的边权值最小,选中这条边,把节点7加入集合U={1,2,7}中,V-U={3,4,5,6}。
如此下去,直到 U=V 结束,选中的边和所有的节点组成的图就是最小生成树。这就是 Prim 算法。
直观地看图,很容易找出集合 U 到 集合 U-V 的边中哪条边的权值是最小的,但在程序中穷举这些边,再找最小值,则时间复杂度太高。可以通过设置数组巧妙解决这个问题,closet[j] 表示集合 V-U 中的节点 j 到集合 U 中的最邻近点,lowcost[j] 表示集合 V-U 中节点 j 到集合 U 中最邻近点的边值,即边(j,closest[j]) 的权值。
例如在上图中,节点 7 到集合 U 中的最邻近点是2,cloeest[7]=2。节点 7 到最邻近点2 的边值为1,即边(2,7)的权值,记为 lowcost[7]=1,如下图所示。
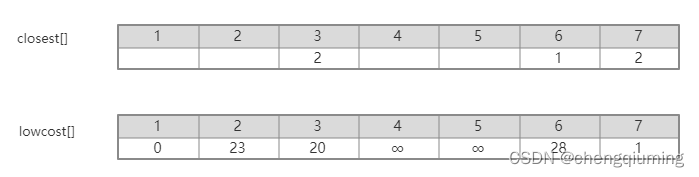
所以只需在集合 V - U 中找到 lowcost[] 只最小的节点即可。
3. 算法步骤
1.初始化
令集合 U={u0},u0 属于 V,并初始化数组 closest[]、lowcost[]和s[]。
2.在集合 V-U 中找 lowcost 值最小的节点t,即 lowcost[t]=min{lowcost[j]},j 属于 V-U,满足该公式的节点 t 就是集合 V-U 中连接 U 的最邻近点。
3.将节点 t 加入集合 U 中。
4.如果集合 V - U 为空,则算法结束,否则转向步骤 5。
5.对集合 V-U 中的所有节点 j 都更新其 lowcost[] 和 closest[]。if(C[t][j]<lowcost[j]){lowcost[j]=C[t][j];closest[j]=t;},转向步骤2。
按照上面步骤,最终可以得到一棵权值之和最小的生成树。
4.图解
图 G=(V,E)是一个无向连通带权图,如下图所示。
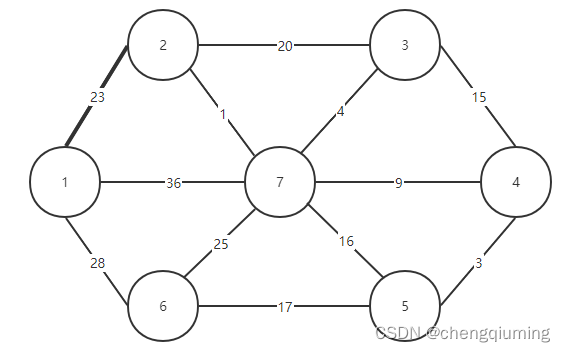
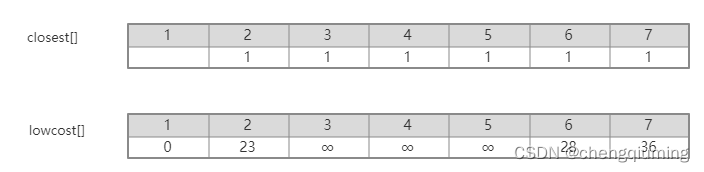
1 初始化。假设 u0=1,令集合 U={1},集合 V-U={2,3,4,5,6,7},s[1]=true,初始化数组 closest[]:除了节点1,其余节点均为1,表示集合 V-U 中的节点到集合 U 的最邻近点均为1.lowcost[]:节点1到集合 V-U 中节点的边值。closest[] 和 lowcost[] 如下图所示。
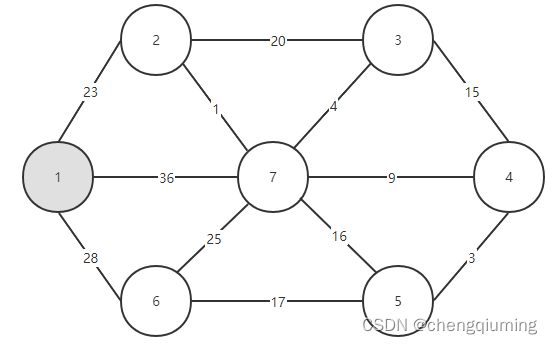
初始化后的图为:
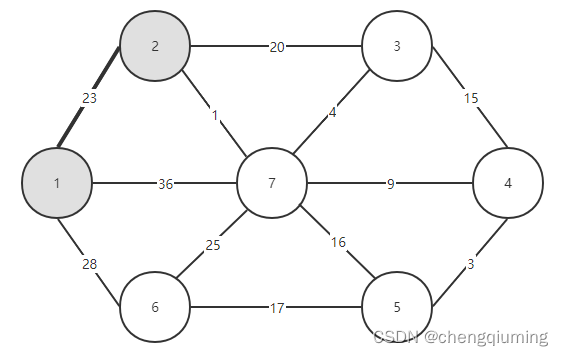
2 找 lowcost 最小的节点,对应的 t=2,选中的边和节点如下图。
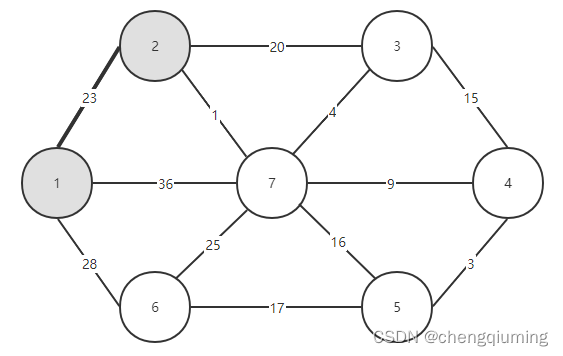
3 加入集合U中。将节点 t 加入集合 U 中,U={1,2},同时更新 V-U={3,4,5,6,7}
4 更新。对 t 在集合 V-U 中的每一个邻接点 j,都可以借助 t 更新。节点 2 的邻接点是节点 3 和节点7。
C[2][3]=20<lowcost[3]=无穷大,更新最邻近距离 lowcost[3]=20,最邻近点 closest[3]=2;
C[2][7]=1<lowcost[7]=36,更新最邻近距离 lowcost[7]=1,最邻近点 closest[7]=2;
更新后的 closest[] 和 lowcost[] 如下图所示。
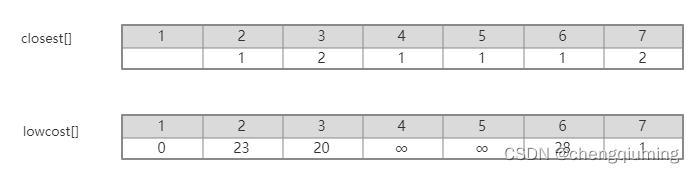
更新后的集合如下图所示:
5 找 lowcost 最小的节点,对应的 t=7,选中的边和节点如下图。
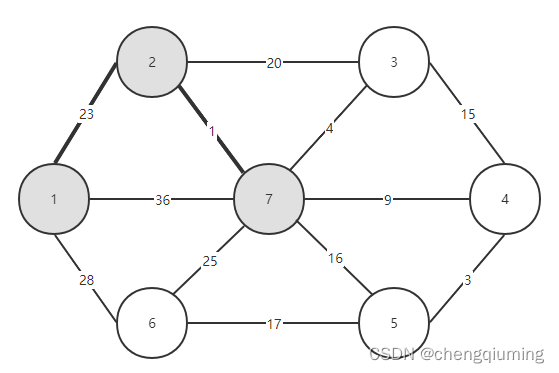
6 加入集合U中。将节点 t 加入集合 U 中,U={1,2,7},同时更新 V-U={3,4,5,6}
7 更新。对 t 在集合 V-U 中的每一个邻接点 j,都可以借助 t 更新。节点 7 的邻接点是节点 3、4、5、6。
- C[7][3]=4<lowcost[3]=20,更新最邻近距离 lowcost[3]=4,最邻近点 closest[3]=7;
- C[7][4]=4<lowcost[4]=无穷大,更新最邻近距离 lowcost[3]=9,最邻近点 closest[4]=7;
- C[7][5]=4<lowcost[5]=无穷大,更新最邻近距离 lowcost[3]=16,最邻近点 closest[5]=7;
- C[7][6]=4<lowcost[6]=28,更新最邻近距离 lowcost[3]=25,最邻近点 closest[6]=7;
更新后的 closest[] 和 lowcost[] 如下图所示。
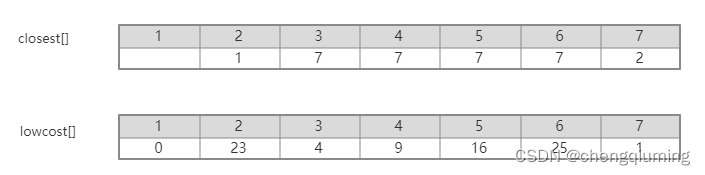
更新后的集合如下图所示:
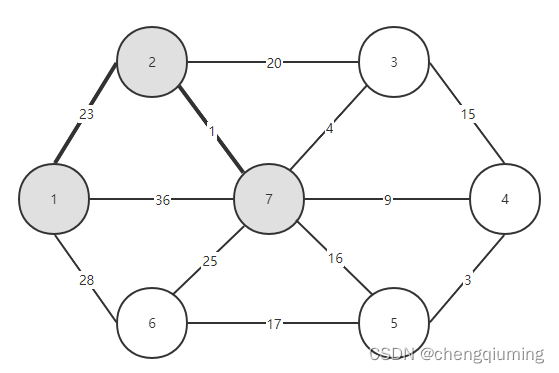
8 找 lowcost 最小的节点,对应的 t=3,选中的边和节点如下图。
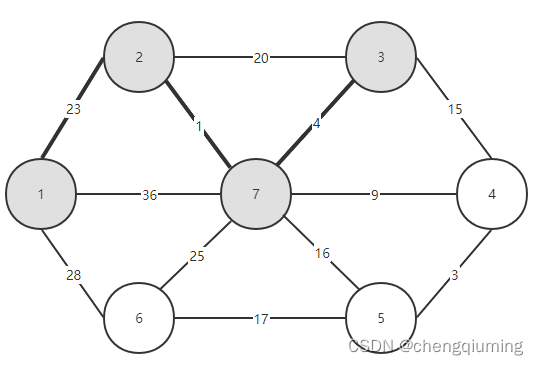
9 加入集合U中。将节点 t 加入集合 U 中,U={1,2,3,7},同时更新 V-U={4,5,6}
10 更新。对 t 在集合 V-U 中的每一个邻接点 j,都可以借助 t 更新。节点 3 的邻接点是节点 4。
C[3][4]=15>lowcost[4]=9,不更新
closest[] 和 lowcost[] 数组不改变。
更新后的集合如下图所示:
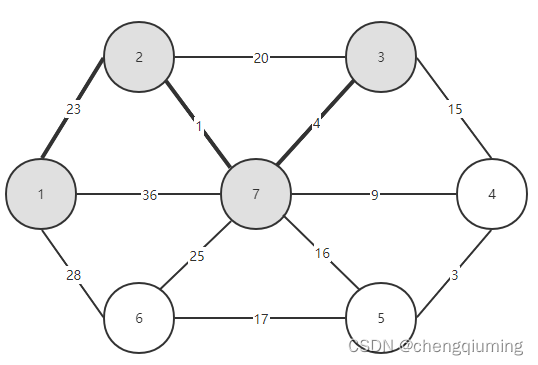
11 找 lowcost 最小的节点,对应的 t=4,选中的边和节点如下图。
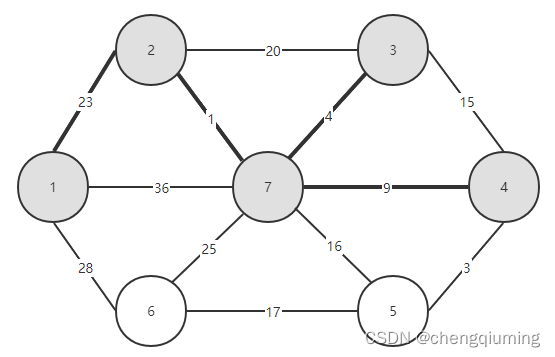
12 加入集合U中。将节点 t 加入集合 U 中,U={1,2,3,4,7},同时更新 V-U={5,6}
13 更新。对 t 在集合 V-U 中的每一个邻接点 j,都可以借助 t 更新。节点 4 的邻接点是节点 5。
C[4][5]=3<lowcost[5]=16,更新最邻近距离 lowcost[5]=3,最邻近点 closest[5]=4;
更新后的 closest[] 和 lowcost[] 如下图所示。
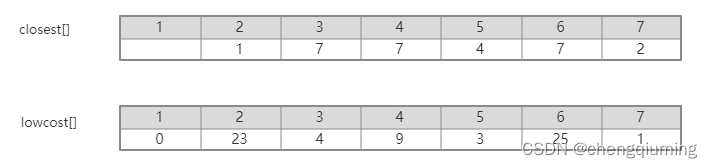
更新后的集合如下图所示:
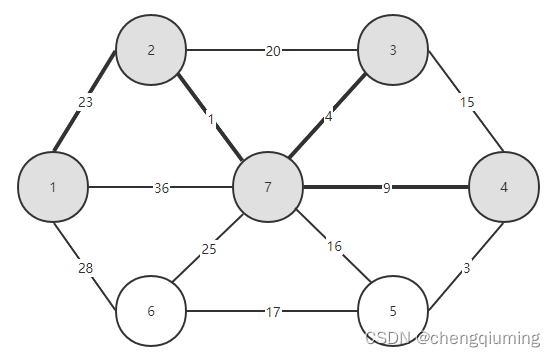
14 找 lowcost 最小的节点,对应的 t=5,选中的边和节点如下图。
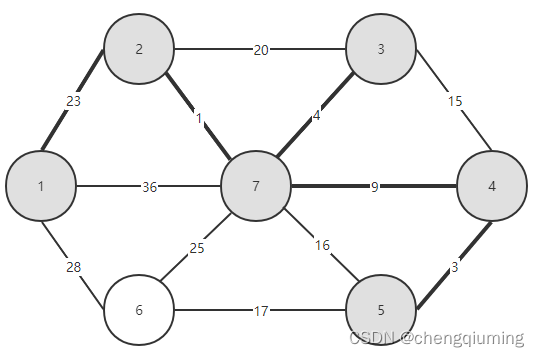
15 加入集合U中。将节点 t 加入集合 U 中,U={1,2,3,4,5,7},同时更新 V-U={6}
16 更新。对 t 在集合 V-U 中的每一个邻接点 j,都可以借助 t 更新。节点 5 的邻接点是节点 6。
C[5][6]=17<lowcost[6]=25,更新最邻近距离 lowcost[6]=17,最邻近点 closest[6]=5;
更新后的集合如下图所示:
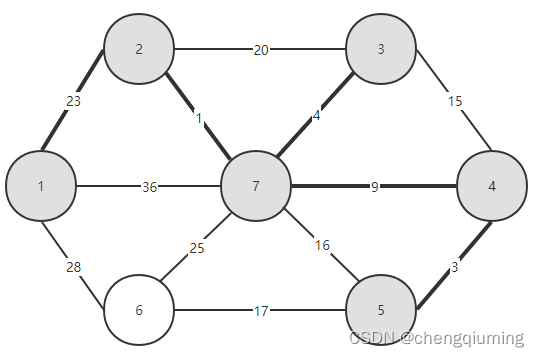
17 找 lowcost 最小的节点,对应的 t=6,选中的边和节点如下图。
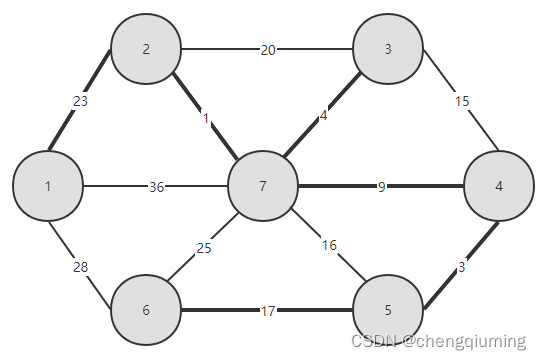
18 加入集合U中。将节点 t 加入集合 U 中,U={1,2,3,4,5,6,7},同时更新 V-U={}
19 更新。对 t 在集合 V-U 中的每一个邻接点 j,都可以借助 t 更新。节点 6 在集合 V-U 中无邻接点。不用更新 closest[] 和 lowcost[] 。
20 得到的最小生成树如下。最小生成树的权值之和为 57.
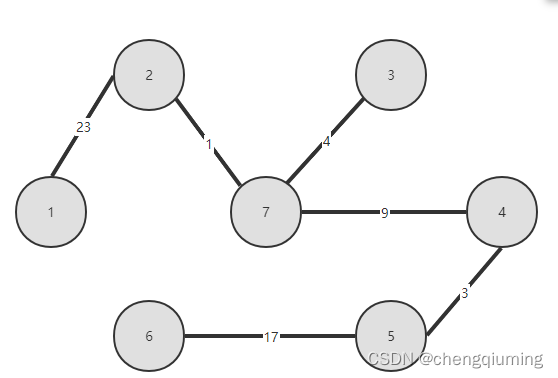
Prime 算法实现
1.构建后的图
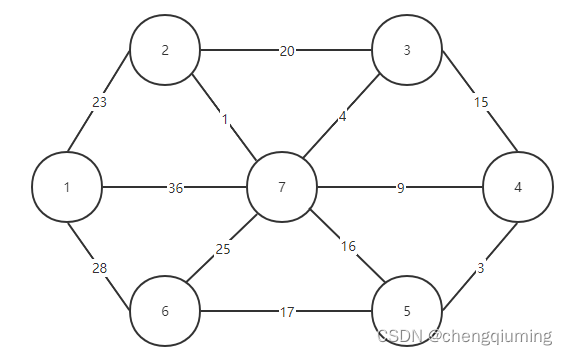
2.代码
package graph.prim;
import java.util.Scanner;
public class Prim {
static final int INF = 0x3f3f3f3f;
static final int N = 100;
// 如果s[i]=true,说明顶点i已加入U
static boolean s[] = new boolean[N];
static int c[][] = new int[N][N];
static int closest[] = new int[N];
static int lowcost[] = new int[N];
static void Prim(int n) {
// 初始时,集合中 U 只有一个元素,即顶点 1
s[1] = true;
for (int i = 1; i <= n; i ) {
if (i != 1) {
lowcost[i] = c[1][i];
closest[i] = 1;
s[i] = false;
} else
lowcost[i] = 0;
}
for (int i = 1; i < n; i ) {
int temp = INF;
int t = 1;
// 在集合中 V-u 中寻找距离集合U最近的顶点t
for (int j = 1; j <= n; j ) {
if (!s[j] && lowcost[j] < temp) {
t = j;
temp = lowcost[j];
}
}
if (t == 1)
break; // 找不到 t,跳出循环
s[t] = true; // 否则,t 加入集合U
for (int j = 1; j <= n; j ) { // 更新 lowcost 和 closest
if (!s[j] && c[t][j] < lowcost[j]) {
lowcost[j] = c[t][j];
closest[j] = t;
}
}
}
}
public static void main(String[] args) {
int n, m, u, v, w;
Scanner scanner = new Scanner(System.in);
n = scanner.nextInt();
m = scanner.nextInt();
int sumcost = 0;
for (int i = 1; i <= n; i )
for (int j = 1; j <= n; j )
c[i][j] = INF;
for (int i = 1; i <= m; i ) {
u = scanner.nextInt();
v = scanner.nextInt();
w = scanner.nextInt();
c[u][v] = c[v][u] = w;
}
Prim(n);
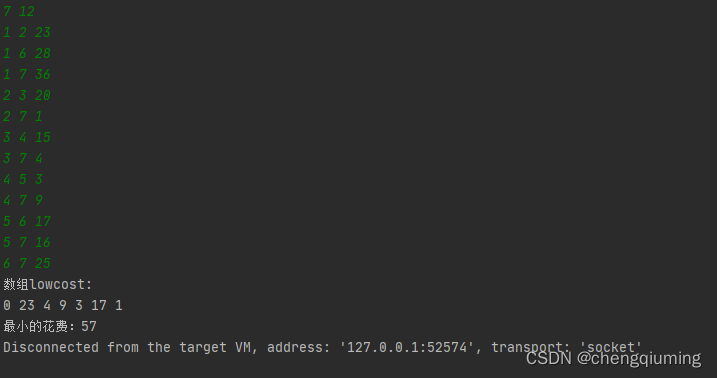
System.out.println("数组lowcost:");
for (int i = 1; i <= n; i )
System.out.print(lowcost[i] " ");
System.out.println();
for (int i = 1; i <= n; i )
sumcost = lowcost[i];
System.out.println("最小的花费:" sumcost);
}
}3.测试
以上就是Java中Prime算法的原理与实现详解的详细内容,更多关于Java Prime算法的资料请关注Devmax其它相关文章!