ORM是O和R的映射。O代表面向对象,R代表关系型数据库。二者有相似之处同时也各有特色。就是因为这种即是又非的情况,才需要做映射的。
理想情况是,根据关系型数据库(含业务需求)的特点来设计数据库。同时根据面向对象(含业务需求)的特点来设计模型(实体类)。然后再去考虑如何做映射。但是理想很骨jian感dan,现实太丰fu满za。
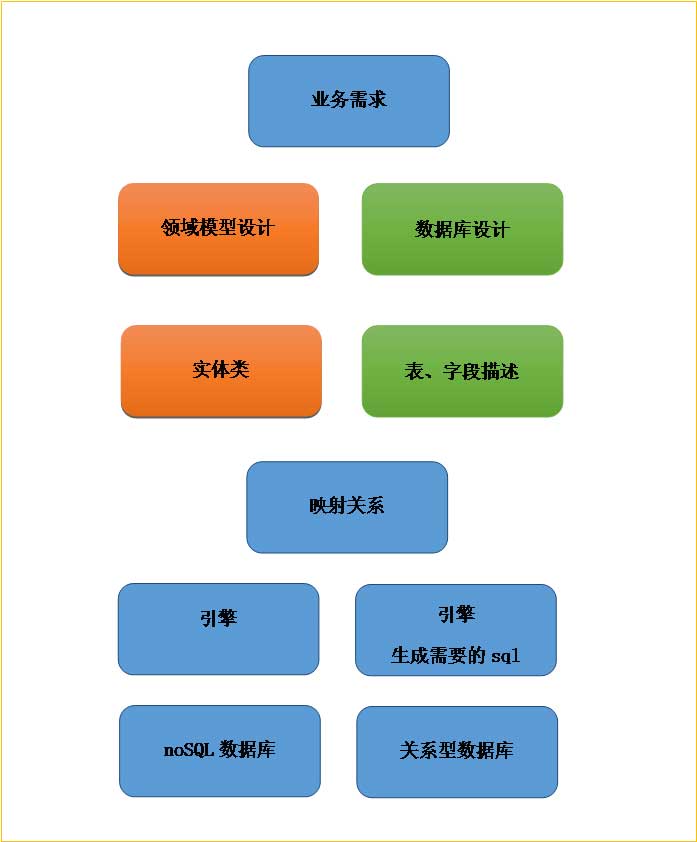
没见哪个ORM是这么做的,也没见哪位高手会这么做设计。那么实际情况是什么样子的呢?以.net的Entity Framework为例。
DB frist,就是先设计好数据库,然后根据库里的表、主外键等自动创建实体类。然后可以通过LinQToSQL来操作。这样创建出来的实体类显然缺乏面对对象的特色。
Code frist,就是先设计实体类,然后根据实体类和特性来自动创建表和主外键、约束等。而为了严谨,定义实体类的时候需要说明一下主外键等具有关系型特色的东东。
如下图
现在想用node来做一套引擎。刚刚接触node,估计会有现成的orm吧,不知道他们是怎么做的,先不管他们了,先把自己的思路弄清楚再说,恩恩。
为啥要选择node呢?以为他原生支持json。Json在前端那是主场,js原生支持json,各种操作都非常流畅舒服。但是json到了后端(C#)就麻烦了,C#原生不支持json,只能作为字符串,或者实体类序列化的形态。这就需要转来转去的,很是麻烦。
而采用node那么后端也可以用js来编码,也就是说会原生支持json。这就舒服多了。想想,前端创建json(实体类),然后整个提交给后端,后端接到json直接进行处理(安全验证、业务处理),然后直接持久化。是不是很爽!
采用node还有一个好处,那就是他可以在运行时定义实体类的属性,比如增加属性。这个在C#里是无法实现的。
为啥一定要运行时可以修改实体类?因为这样做可以避免实体类数量爆炸。
打开你的项目,数一数定义了多少的实体类?是不是项目越大实体类就越多?当需要发生变化,需要给实体类增加一个属性的时候,是不是需要各种改代码?虽然VS可以帮我们做很多工作。
所以说还是在运行时可以随意修改实体类的好,这样可以极大地避免修改代码的问题。(因为根本就没有啥代码)
这一篇主要是说思路,所以先简单设计一个json来表示一下。
设计这个json的目的是,引擎可以根据json的情况来拼接成SQL,然后交给数据库处理。
{
"operationMode":"add",// add\update\delete\select
"tableCount":1, //支持多表的级联添加、修改
"fieldInfo":[{//主表的字段,参与操作的字段,不参与的不用写。第一个字段是主键(不支持多主键)
"tableName": "t1", //表名。
"primaryKey":"id",//主键字段名。我不想把主键字段名限制为必须是“ID”
"_sqlCache": "" ,//缓存的sql语句,每次都拼接sql也挺烦的,弄个缓存存放拼接好的sql。
"fieldList":{ //涉及到的字段,并不需要把表里的字段都放进来,根据业务需求设计
//客户端提交的json与之对应
"field1Name":"field1Value",
"field2Name":"field2Value"
}
},
{ //从表的字段,可以不设置
"primaryKey": "id", //主键字段名。我不想把主键字段名限制为必须是“ID”
"foreignKey": "foreignKeyid", //主键字段名。我不想把主键字段名限制为必须是“ID”
"_sqlCache": "", //缓存的sql语句,每次都拼接sql也挺烦的,弄个缓存存放拼接好的sql。
"fieldList": { //涉及到的字段(不含外键字段),并不需要把表里的字段都放进来,根据业务需求设计
//客户端提交的json与之对应
"field1Name": "field1Value",
"field2Name": "field2Value"
}
} // 从表的字段,参与操作的字段,不参与的不用写。第一个字段是主键,第二个字段是外键
],
"findCol":[{
"colName":"col1",
"key1":"abc",
"key2":"abc", //范围查询时使用,比如从几号到几号
"findKind":" {colName} like {key}" //查询方式:like、not Like、in、=、between等
}]
}
一般的ORM是以实体类为核心,要求实体类的完整,就说一个实体类要和一个完整的表做映射。比如要下架一个商品,一般的做法是先把这个商品从数据库里读取出来实例化之后,修改标记属性(字段),然后再把整个实体类持久化(保存到数据库)。
但是SQL怎么写呢?一个update就可以了,不用读取数据的,这样效率就有点损耗。
那么如果要把一个分类的商品都下架呢?要把这个分类里的商品都折腾出来,然后批量改属性值,在批量持久化。
如果写SQL语句呢?还是那一句SQL,只不过是把查询条件换一下,还是不需要折腾数据。这种情况下效率的差别就很大了。
而我的这个思路呢,并不是以面向对象为核心的,而是以关系型数据库为核心。
就是说不会把实体类和表做整体的映射,而是会把属性和字段做映射。就是说把一个表里的部分字段拿出来,做成一个实体类,然后进行操作。比如下架商品的例子
表:商品表
字段:isxiajia = 1
条件:id=1(单商品下架) cate=2 (按照分类下架)
然后生成update语句就可以了。
这是一个独立的“实体类”,这个类里面并不需要商品的其他属性,因为只是下架操作。另外查询条件也完全放开,不是仅仅依据ID查询,还可以按照其他字段来查询,比如分类字段。这样效率就可以得到提升。
总结
以上所述是小编给大家介绍的使用Node.js实现ORM的一种思路详解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对Devmax网站的支持!